背景
我们有一块业务维护了上百台边缘 AI 服务器分布在全国各地,其中应用的管理和升级使用的是 clusternet ,所以每一台边缘服务器都是一个独立的 k3s server。
问题一
上周五发现其中一台边缘服务器监控告警,发现有一个 Pod(算法引擎) 一直处于 Crash 状态。通过命令查看容器日志,其中错误信息如下:
jq: error while loading shared libaries: /usr/lib/x86_64-linux-gun/libjq.so.1: file too short由于此 Pod 挂载了宿主机上 /usr/lib/x86_64-linux-gun 目录的一些文件,虽然使用的是 subPath 方式,但是保险起见。最开始还是先把所有的挂载取消了,但是仍然报错。这时候怀疑是镜像有问题,所以就使用 k3s ctr images export image.tar {image-id} 命令,同时在问题机器和正常机器上执行,然后对比两边文件的 MD5 值,发现一样。然后,就认为镜像没问题了。(这里进入误区了。。。)仍然认为尽管没全部挂载宿主机上的 /usr/lib/x86_64-linux-gun 目录文件,但是还是受影响了,所以还在宿主机上更新 apt-get update 命令。
后面,意识到不正路子有点走歪了。因为容器启动失败,所以一开始也没有能够进入容器中进行查看文件情况。所以,想着先修改一下 command 配置,能够进入容器中查看出问题的文件情况。所以,配置 deployment 中的 command 参数如下:
command: ["/bin/sh", "-c", "sleep 3600"]然后,exec 进入到容器中,ls -lht /usr/lib/x86_64-linux-gun 发现好多零字节文件,如下:
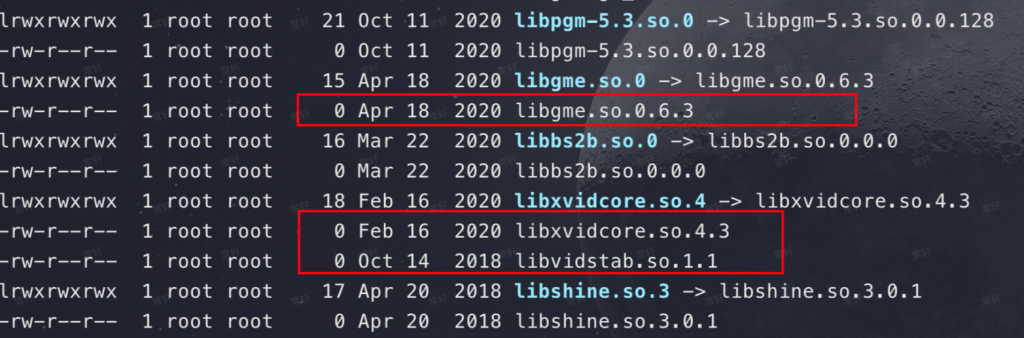
所以,导出的镜像没问题并不表示由它创建的容器不会有问题。此时,还没功夫探究为什么会出现这个现象(因为影响现场使用了),所以想着先把所有应用都重置掉,然后再把镜像都删除掉(k3s ctr images rm {image-id}、k3s ctr images prune -all),最后把应用再重新下发下去岂不是就能解决了。
问题二
果然,还是我过于乐观了!
当我执行完上面系列操作后,发现由于算法引擎镜像中打包了许多模型体积十分庞大,正好出问题机器的网络还比较差。为了避免争抢网络资源,我将算法引擎的副本书设置为 0,通过 wget 下载正常机器上 export 出来的 tar 包。(这里也犯傻了,应该直接导入上面 export 出来的包,但是当时还是怀疑有问题。)
当下载完成后,使用 k3s ctr -n k8s.io images import image.tar 命令进行导入,不出意外的话出意外了,应用还是没起来。但是这次的报错变样了:
exec /vse/run.sh: exec format error
往往在可执行文件和系统架构不一致的时候才会出现的异常,怎么出现在这里了?而且可以确保镜像和服务器肯定都是 x86_64 架构的。(删除重新导入过、怀疑过导入导出有问题、怀疑过镜像被人动过手脚、检查镜像ID也没问题…)一时间,没了头绪…
后来发现一个比较奇怪的事情,就是我使用 k3s ctr images rm {image-id}、k3s ctr images prune -all 命令好像没办法彻底删除镜像,因为删除完一旦把 deployment 副本数由 0 设置为 1 后,就没有拉取镜像的过程,直接就启动接着报错了。(当时发现了这个问题,但放过它了,因为看了一些文档和帖子也都说我使用的命令就是删除镜像的,就一直被这个架构不一致表面问题给缠住了)
确实没有什么好的办法了,就跟同事讨论了一下,同事也没有很好的办法来解决问题。这时候我发现,因为反复删除/下发应用,导致有几个应用的镜像一直拉取失败。既然,这个问题解决不了,就先看看为什么拉取失败,失败原因如下:
Warning Failed 2m19s (x4 over 3m50s) kubelet Failed to pull image "registry.xxx.com/ssss:1.3.2": rpc error: code = FailedPrecondition desc = failed to pull and unpack image "registry.xxx.com/ssss:1.3.2": failed commit on ref "layer-sha256:ea9db98297acf42be2958db784df136892ea4ce32f64f2d8f2cc71f7719e483d": unexpected commit digest sha256:4b9a75f66b1d82c73e0f12a37b0ef6f9c3f1dae3c3b476c5c3ceda7eb2a24b87, expected sha256:ea9db98297acf42be2958db784df136892ea4ce32f64f2d8f2cc71f7719e483d: failed precondition大概意思就是说 containerd 在解包镜像层时检测到数据完整性问题:实际层的 digest(sha256:4b9a75f66…)与清单中预期的 digest(sha256:ea9db98297…)不一致。这通常说明镜像层在存储或传输过程中发生了损坏,或者镜像仓库中的数据与预期不符。
镜像仓库的数据损坏概率太小了,所以我就想着先清理一下本地缓存数据,这里问了一下 ChatGPT,关键的来了,它告诉不仅要 k3s ctr -n k8s.io images rm ,还要使用 k3s ctr -n k8s.io content ls 来查看,手动清理未引用的内容。这时候我惊奇的发现,我明明已经把当前服务器上所有的应用服务给删掉了,以及使用 rm 和 prune 命令清理了镜像。执行 k3s ctr -n k8s.io content ls 命令后仍然能看到一些算法引擎镜像层。为了清理的更干净,就全部删掉了。然后,再次重新下发应用,这次发现应用终于正常了。
经验
使用 ctr 处理镜像时,不止是 image rm 和 image prune 还有 content 命令哦,AI 很好用,但是也要学会如何问问题,不然也很难得到你想要的答案。